The following is a critique of an API documentation page from a developer's point of view.
About me: I am a programmer-writer. That means I am technical writer. And also a developer. I specialize in developer-to-developer documentation, such as API documentation. That means, I get to both look at and to write API documentation from a developer's perspective. What they like and don't like about it. That insight gives me the advantage. I try to do the same here. I believe many of the points I mention would not be obvious to writers with a limited development background. Nothing wrong with that per se. But some details may get overlooked for the developer audience. It's important to note what is missing and why it's relevant to developers.
It’s interesting what companies consider acceptable. On the one hand, they have no hesitation hiring top-notch, expensive developers. On the other, they settle for substandard documentation. But these aren’t two separate concerns—they go together. In a very real sense, the documentation is the product. Remember, APIs are not discoverable. That means client developers won’t know the call names, the parameters, what they do, or their values—unless we tell them. And we tell them through documentation.
So, the mystery is: why do CEOs allow bad documentation?
One reason—let me be blunt—may be that they just don’t care. But that attitude only hurts the company. It hurts in unseen ways, which is why it may not be obvious that documentation is the root cause. Problems stemming from poor documentation may be baked into their current operations. For example, support costs may be high. Why? Because client developers need information. If they don’t get it from documentation, they call the company. That involves support staff or even developers—expensive resources. And if the company has always had poor documentation, they may wrongly view their support costs as normal.
Stripe, often seen as the leader in API documentation, tracks an interesting metric: the number of trial users who don’t continue with them. They view the loss of potential customers as a documentation failure. Presumably, potential client developers know what they need and can recognize bad documentation immediately. They know poor documentation means implementation issues down the line—and they avoid it from the start. In other words, a company may be losing customers purely because of their documentation. Companies aren’t smarter than their clients, and it's hubris to think otherwise. If you're about to argue that proper documentation costs money—know this: it doesn't just cost money, it makes money. It just does it differently than the sales department. Clients are going to solve their problems—with or without the company. We want it to be with the company.
Another possible reason for bad documentation is that CEOs simply don't know how to get good documentation. I’d like to think this is the real issue. They understand what developers do, but they don’t understand what API documentation is—or the limitations of traditional technical writers. So why would we expect them to create good, much less great, API documentation? If they assume it's just technical writing, they hire technical writers to write it because that's what they know to do. It's more about rote than write. Unsurprisingly, this yields technical writing results. The problem is, technical writing results don’t connect with client developers. It misses details that developers need.
API documentation is not technical writing. It’s API documentation writing. The key differences are the dependence on code and a deep understanding of development practices. There are countless nuances and subtleties—and each one matters to developers. How can it not? You're writing to developers about development. It needs to be precise and it needs to speak their language.
The following are examples of common API documentation problems that directly affect client developers. Great documentation anticipates developers’ questions, doesn’t make them hunt for answers, and avoids unnecessary scrolling.
They pack several mistakes into one page, sometimes into one field. No time wasting for them.
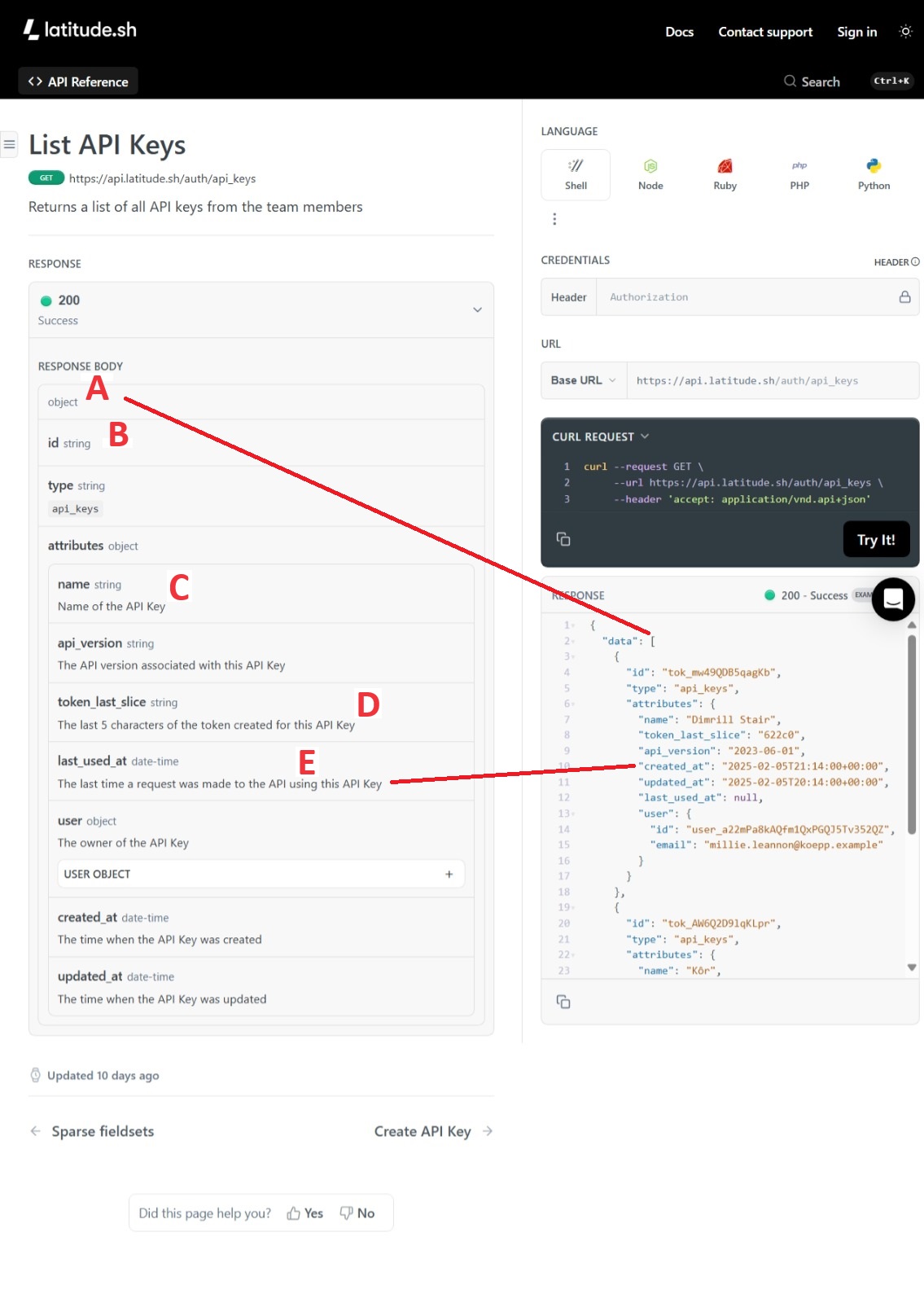
A.This is the return field. Calling this an 'object' is substantially wrong.
Foremost, we must keep in mind, why we even have documentation. The client needs two bits of information from the page.
Yes, the return is an object. But then again, almost everything in REST calls is an object. So, that doesn't help. That makes it too vague and, so, offers little help to the client developer. To be more precise, this is an array. You can tell by the open hard bracket. But even that is not precise enough. It's an array of objects. As opposed to an array strings or numbers. But even that isn't precise enough. It's an array of a specific kind of objects.
This is where we run into another problem. The documentation doesn't name the object in this case. This is fine for complying to OpenAPI standards. The object doesn't have to have a name. The developers can define theirs as an array of objects. This is a horrible practice though. In-house developers should really name all their objects.
Notice what happened, though. This is an instance when the client must stop and figure out a value. The documentation has failed them.
At least we know named objects exist and one in-house developer knows this. Later in the documentation, there is an object named user. Yea indeed. This API uses and supports named objects.
But you're thinking to yourself "I can find this out from the example to the right." In this case, yes. It happens to be visible on the screen. The returned object is clearly named 'data'. This is important when they start identifying entries within the array. The client may need to identify `data.id` or `data.attributes.name`. But it's an array remember? To be correct, those identifiers need an index such as `data[0].id` or `data[6].attributes.name`.
What if the example wasn't just to the right? What if the client had to scroll up or down, or both to find it? It'd be an annoyance. It'd be another instance when the client must stop and figure out a value. A client could know this just by looking at the documentation text, if the value had been included there. They would not have to also reference the example. Why make them do in two steps when one would have worked? This is an aspect writers would have known about if they were familiar with programming concepts. Ignore development at your own risk.
B. 'id' should never stand alone. It should always be qualified such as 'keyId' or 'userId'. By itself, it's not very precise. Some will defend 'id' as the reader will understand it in context. Perhaps. Some of the time. But we're writing for clarity. 'keyId' will always be more understood in any context and will always be precise.
Field names are generally not the realm of the technical writer. But they should be. We're advocates for the client and it's our job to make all the concepts clear and actionable. That means, we have every right, if not an obligation, to make that happen. We can apply that to all aspects of our job, not only just the documentation itself, but the code as well. We can push back on developers for this issue. This must be done before it gets merged into the code. We can do that by reviewing the PRs, catching them before they get approved.
C. All sentences should be fully, complete, English-complying sentences. All the time. Why would any writer not do this?
D. This field returns the last five characters of the API key. Since our job is to anticipate questions, we can fairly ask: what does this do and why do we need it?
To answer questions like this, I divide issues into common concepts and obscure concepts.
Common concepts are just that. Common and probably don't need much explanation for the reader. On this page, I'd say the API key is a common concept. I believe most of the readers know what an API key is for. We might have to explain how they were generated, or where to use them, but not the concept itself. The token_last_slice might need an explanation. I had to stop and think about it for a moment. That's always an indication that something more is needed.
I don't know this call but I'd guess it's a reminder for the client of what the API key value is. I can accept that the API key is one of the sensitive pieces of information, perhaps along with the client secret and password. That would make sense not to show the complete value. Beyond that, when is it used? Is it for our reminder only? This merits an additional sentence or two.
This is what I mean when I make the critique that nothing can really be explained by a single sentence.
There's always more than can be added.
For example, take the humble phone number.
The field can be named phoneNumber, but clientPhoneNumber, mobilePhoneNumber, or businessPhoneNumber is clearer.
The name aside, anticpate the next question: What is the format of the number?
There are no fewer than 15 ways an American phone number can be described.
In the documentation, include example formats:
(XXX) XXX-XXXX, XXX-XXX-XXXX, XXX.XXX.XXXX, XXX XXX XXXX, XXXXXXXXXX, +1 (XXX) XXX-XXXX,
to show only a few.
And this becomes confusing, yes.
Here is the regex for some of the possible formats:
^\s*(?:\+?1|001)?[\s.-]*\(?\d{3}\)?[\s.-]*\d{3}[\s.-]*\d{4}(?:\s*(?:x|ext\.?|extension)\s*\d{1,6})?\s*$
These are another instances when the client must stop and figure out a value. Looking at API documentation in more lofty terms, it sells peace of mind. The developer should know what to do now, what values to use, what's going to be returned, and what to do next. Great documentation addresses these in at least two important ways.
E. This case is about the use of examples, or rather, not having examples.
The field returns literally the last time, or more precisely, the timestamp when the call was used the last time. The data type is clearly date-time. But it's not clear what the format is. This is another instance when the client must stop and figure out a value. If I were to ask you to get the day value from this field, you couldn't do it. You need more information.
Now, to get that information, the client must do extra work. It's common to define the date-time in introductory material. But that's such a technical writer way of thinking. But we're not technical writers, we're API documentation writers. We require a new way of thinking.
Not that any of that would have mattered. There is no link or indication where the format is covered. Not having those links isn't my criticism. In fact, I advocate not using links or references like this. That just makes them do more work.
My criticism isn't even that the format isn't included. Time formats are varied to begin with. Even if it is specified, for example, ISO 8601, that doesn't describe it enough. ISO 8601 formats also vary widely. The following are all valid ISO 8601 formats:
I can hear the comments now for the third way: The client could use the example to the right. Perhaps. There’re three problems with that.
We finally get to my criticism: There's no example in the field description. Clients need examples in the field description. It's where they're already looking. Why would you want to make them work more for it? In groups I'm either manager or lead of, I require that all fields have examples. No exceptions.
Listing these would have resolved this issue in a single glance:
This is a definitive description of the format. Developers will know this format. They just needed to know which format to use.
This is another instance when the client must stop and figure out a value. There's now been at least three instances in a very brief that the documentation fails to deliver information to the reader. Do you see how this adds up? We could have told the clients the exact information. Instead, this page is costing them time and effort. "We're here for their convenience. Not ours." That means we must do whatever we need to do to be clear, regardless of how hard it is for us.